
Nome: Alexandre Murakami - NoUSP: 300954
Turma: BCC/2000
Prof.: Carlos Eduardo Ferreira
int inverte( int v[], int i, int k, int n);
que, quando aplicada, inverte a ordem dos elementos v[i], v[i+1], ..., v[i+k-1], caso isso seja possível, e retorna 1. Se i+k-1 >= n, a função não altera a ordem dos elementos no vetor e retorna 0.
Os objetivos deste exercicio-programa são:
Várias funções, como a função inverte(), foram implementadas nos arquivos UnitInverte.c / UnitInverte.h. Para usá-las, os makefiles dos programas devem incluir o arquivo UnitInverte.c. No Lcc-Win, este arquivo deve ser incluído no projeto de cada programa (Project / Add files).
A função imprimeHora() (arquivo UnitInverte.c), contém o comando gettime() do C++Builder, sendo não compatível com o padrão C ANSI. Para utilizá-la, deve-se incluir a seguinte linha no arquivo UnitInverte.h:
#define VERSAO_DOS
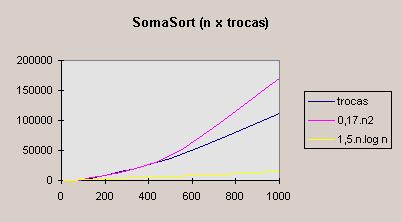
Como mostra o gráfico a seguir, o algoritmo não conseguiu superar o desempenho do BubbleSort tradicional. O número de trocas (chamadas à função inverte()), é O(n2).
Na seqüência acima, apenas os números 8 e 4 estão fora de lugar. A partir daí, o SuperBubbleSort age como um BubbleSort normal, o que não é eficiente. Uma solução para esse problema seria detectar a situação descrita (talvez após vários loops com inversões de k = 2) e, a partir daí, adotar um algoritmo de ordenação diferente, como uma inserção binária.
Foram criadas duas variações do SuperBubbleSort. O primeiro algoritmo, chamado de SupperBubbleSort2, após uma inversão, começa verificando o último elemento da seqüência invertida. No SuperBubbleSort, a verificação começa a partir do elemento seguinte à inversão. Essa modificação não provocou melhorias sensíveis no desempenho do programa.
A segunda variação foi chamada de MaxBubbleSort. Nela, em cada loop o programa procura a maior seqüência invertida do vetor, aplicando a função inverte() nessa seqüência. O SuperBubbleSort, ao contrário, aplica a função inverte() na ordem em que as seqüências são encontradas. O MaxBubbleSort apresentou um desempenho bem inferior ao algoritmo original.
Tomemos, por exemplo, a seqüência 7, 5, 3, 8, 5, 1. A soma da primeira metade é 7+5+3 = 15. A soma da segunda metade é 8+5+1 = 14. Como 15 > 14, a seqüência seria invertida.
É difícil garantir a corretude desse algoritmo. Podemos dizer que, se a seqüência escolhida tiver apenas dois elementos invertidos, essa seqüência será corretamente invertida. Acredita-se também que os elementos maiores tendem a ser levados para o final do vetor. Os testes do programa mostraram que a seqüência sempre é ordenada.
Embora o número de troca é inferior a O(n2), o desempenho do algoritmo não é satisfatório. Como, para cada seqüência invertida, o número de comparações é alto. Isso torna o programa extremamente lento, como é mostrado na comparação entre os tempos de execução dos algoritmos (mostrado mais adiante, após a descrição dos algoritmos).
Esta implementação não aproveita as vantagens da função inverte(), de modo que o desempenho apresentado não é muito diferente da versão tradicional. O número de trocas é O(n), enquanto que o número de comparações é O(n2).
SCHILDT, Herbert. C completo e total. São Paulo : Makron, McGraw-Hill, 1990.Neste método, o vetor é ordenado comparando-se elementos distantes de, por exemplo, 3 posições (k = 4). Em seguida, o vetor é ordenado, mas comparando elementos que estão distantes de, por exemplo, 2 posições (k = 3). Finalmente, o vetor é ordenado comparando elementos adjacentes, como num Bubble Sort comum (k = 2). A distância entre os elementos a serem comparados pode variar. As únicas regras são que a distância deve sempre diminuir a cada passo e, no último passo, a distância deve ser 1 (k = 2). O livro citado sugeria, por razões desconhecidas, a seguinte sequência, adotada nesta implementação:
9 (k = 10), 5 (k = 6), 3 (k = 4), 2 (k = 3), 1 (k = 2).
Foram ainda acrescentados alguns números, o que melhorou o desempenho do algoritmo (ver listagem) para vetores grandes (n = 10.000).
O livro citado afirma que o ShellSort apresenta O(n1,2),
sem explicar a causa desse resultado. A implementação feita
apresentou um resultado diferente, aproximadamente O(n1,7).
Este resultado ocorreu provavelmente pelo uso da função inverte(),
que altera de maneira significativa o algoritmo original. No algoritmo
original, para cada valor de k, o vetor era varrido somente uma vez. Nesta
versão, o vetor teve que ser varrido diversas vezes, de maneira
semelhante ao BubbleSort. Mesmo com o desempenho prejudicado, o algoritmo
apresentou bons resultados, sendo o mais rápido dos algoritmos testados.
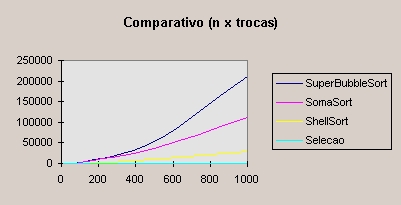
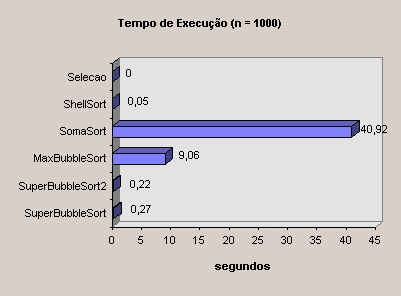
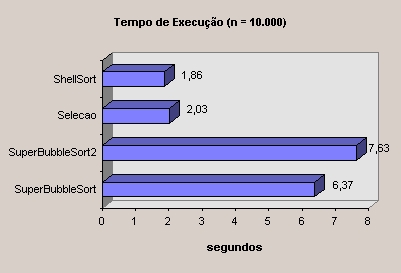
Um segundo teste foi feito entre os algoritmos de melhor resultado, desta vez com n = 10.000.
Como os elementos ordenados não são mais movimentados,
falta espaço para a movimentação dos últimos
elementos do vetor. Para resolver esse problema, é acrescentado
ao final do vetor 2.k elementos. Esses elementos têm valor maior
que qualquer outro elemento do vetor. Dessa forma, ao final da ordenação,
eles estarão posicionados no final do vetor, podendo ser descartados.
Esses elementos foram chamados de "lixo". Observe o exemplo:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
A escolha da seqüência de inversões exige um certo
cuidado. Seja c a posição em que se deseja colocar um determinado
elemento, p a posição desse elemento. Inicialmente, a função
inverte é aplicada repetidamente, até que o número
caia na região c < p < c + 2.k. A partir daí, o valor
de i passado para a função inverte() é calculado segundo
uma função (apresentada na listagem). A figura a seguir mostra
os valores que devem ser subtraídos de p para se obter o valor de
i, para k = 8:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
7 | |||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 | 9 | |||
Inicialmente, deveria se garantir que o problema tivesse solução. Para aplicar um algoritmo semelhante sem o uso do "lixo", a seqüência de movimentos torna-se bem mais difícil. Os elementos já ordenados devem ser também movimentados. Pelo menos para alguns casos, pode-se ter certeza de que o algoritmo não funciona. Por exemplo, se k = n, só haveria uma única inversão possível e a seqüência só seria ordenada se estivesse invertida ou se já estivesse ordenada.
Uma maneira de resolver esse problema seria com o uso de backtracking. Os elementos são ordenados um a um, mas a seqüência de movimentos é determinada de maneira diferente. Para posicionar um elemento, o programa deve testar todas as seqüências de combinações possíveis de inversões que envolvem o elemento em questão. No final, teríamos o elemento e todos os anteriores devidamente posicionados. Supondo que o número de inversões necessárias seja de O(n), o número total de combinações de movimentos seria razoável. Se houvesse uma resposta, ela seria encontrada.
Somente um algoritmo de ordenação com vetor circular foi implementado. Ele é uma adaptação do SuperBubbleSort. Entretanto, o algoritmo praticamente não realiza inversões circulares, apresentando praticamente o mesmo desempenho do algoritmo original.
É extremamente difícil criar um algoritmo com k variável
que realmente aproveite a condição de vetor circular. O critério
de aplicação de uma inversão no meio do vetor deve
ser diferente da inversão nas pontas. Além disso, é
muito difícil criar critérios para a aplicação
de inversões "não simétricas" nas pontas. Por exemplo:
|
|
|
4 | 6 |
|
|
|
Uma inversão com i = 4 e k = 5 seria adequada para a ordenação desse vetor. Mas como criar um algoritmo que chegue a esta conclusão automaticamente?
O algoritmo com k fixo poderia ser semelhante ao sugerido para vetor
não circular (backtracking), com a vantagem de que, para os elementos
do final do vetor, as trocas poderiam ser feitas nos dois sentidos. O problema
com k = n continua possível. Veja o exemplo com n = k = 4. A partir
da inversão da seqüência 1, 2, 3, 4, podemos obter:
| i = 0 | 4 | 3 | 2 | 1 |
| i = 1 | 2 | 1 | 4 | 3 |
| i = 2 | 4 | 3 | 2 | 1 |
| i = 3 | 2 | 1 | 4 | 3 |
Vemos que o resultado para i = 0 e i = 2 são iguais. O mesmo
ocorre para i = 1 e i = 3. Na verdade, isso ocorre sempre. Por isso, só
apresentaremos os resultados para i = 0 e i = 1. A partir do resultado
obtido para i = 0, obtemos as seguintes seqüências:
| i = 0 | 1 | 2 | 3 | 4 |
| i = 1 | 3 | 4 | 1 | 2 |
E a partir do resultado obtido para i = 1, obtemos:
| i = 0 | 3 | 4 | 1 | 2 |
| i = 1 | 1 | 2 | 3 | 4 |
o que nos permite concluir que nem todas as combinações são possíveis (ex: 1, 2, 4, 3).
| seqüência original | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| i = 0, k = 6 | 6 | 5 | 4 | 3 | 2 | 1 | 7 | 8 | 9 |
| i = 3, k = 5 | 6 | 5 | 4 | 8 | 7 | 1 | 2 | 3 | 9 |
Sabemos que a seqüência obtida pode ser resolvida com duas inversões, mas como criar um algoritmo que identifique essas inversões? Poderíamos obter a seqüência mínima de movimentos usando um método de backtracking, isto é, testando todas as combinações possíveis. Mas de que adiantar conhecer a resposta após as dezenas de chamadas à função inverte que o backtracking faria? Este é, portanto, um problema altamente complexo e de difícil solução.